
이전 글을 안 보고 오신 분들은 이전 글부터 봐주세요!
1편. 일본어 단어 암기, 이제는 자동화다
일본어 공부를 하면서 가장 힘든 요소에는 어떤게 있을까요?사람마다 다르겠지만 저에게는 단연코 "단어 암기"였습니다. 교재에 나오는 단어를 외우는 것도 힘든데, 실생활에서 쓰이는 단어는
irukai.tistory.com
일본어 단어 암기를 자동화하려면 가장 먼저 해야 할 일은 기본이 되는 단어 데이터셋을 준비하는 것입니다. 이번 글에서는 제가 어떻게 JLPT 단어 CSV를 준비했고, 여기에 GPT API를 활용해 필요한 정보를 추가하고, 자동화를 위한 데이터 구성까지 다듬었는지 설명하겠습니다.
추가로 제가 사용했던 핵심 코드들도 함께 작성해두었으니, 필요하신 분들은 편하게 사용하셔도 됩니다!
🔤 원본 데이터셋
JLPT 단어는 Kaggle에서 Robin Pourtaud 께서 제공해주신 데이터를 사용했습니다.
https://www.kaggle.com/datasets/robinpourtaud/jlpt-words-by-level?resource=download
JLPT vocabulary by level
Japanese Vocabulary with Furigana and English Translation by JLPT Level
www.kaggle.com
원본 데이터 csv는 다음과 같은 구조를 가지고 있었습니다:
| Original | Furigana | English | JLPT Level |
| 現像 | げんぞう | developing (film) | N1 |
| 原則 | げんそく | principle, general rule | N1 |
| ... | ... | ... | ... |
- Original: 단어의 원형 (한자)
- Furigana: 읽는 법 (히라가나)
- English: 영어 뜻
- JLPT Level: 난이도 (N1 ~ N5)
🎈 데이터 분석
우선 어떤 데이터인지 분석하기 위해서 전처리용으로 Python의 Pandas, Matplotlib 라이브러리를 사용했습니다.
전체 단어는 총 8130개였으며, 중복되는 한자, 히라가나, 뜻이 많았습니다. 그러나, 한자 표기 혹은 읽는 법이 다른 경우가 있어서 따로 제거하진 않았습니다.
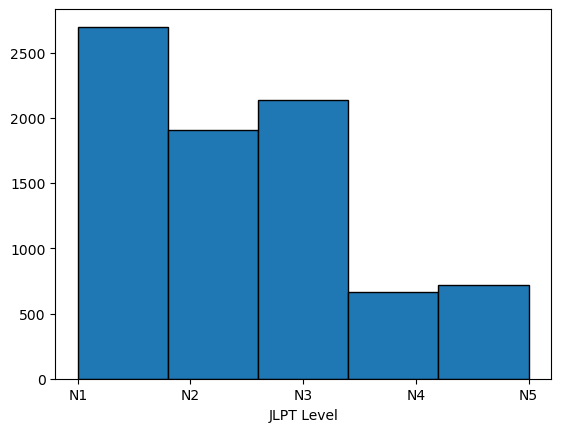
plt.hist(vocab['JLPT Level'], bins=5, edgecolor='black')
plt.xlabel('JLPT Level')
저는 JLPT N2 취득을 목표로하고 있기 때문에 N1 단어들은 제외시켰습니다.
그 결과 N2 ~ N5 범위의 단어 5429개를 얻었습니다.
일반적으로 N2 기출어휘가 약 6000개 정도라고 하니까 요 데이터로도 충분히 학습할 수 있을 것 같네요.
vocab_n2_to_n5 = vocab.where(vocab['JLPT Level'] != 'N1').dropna()
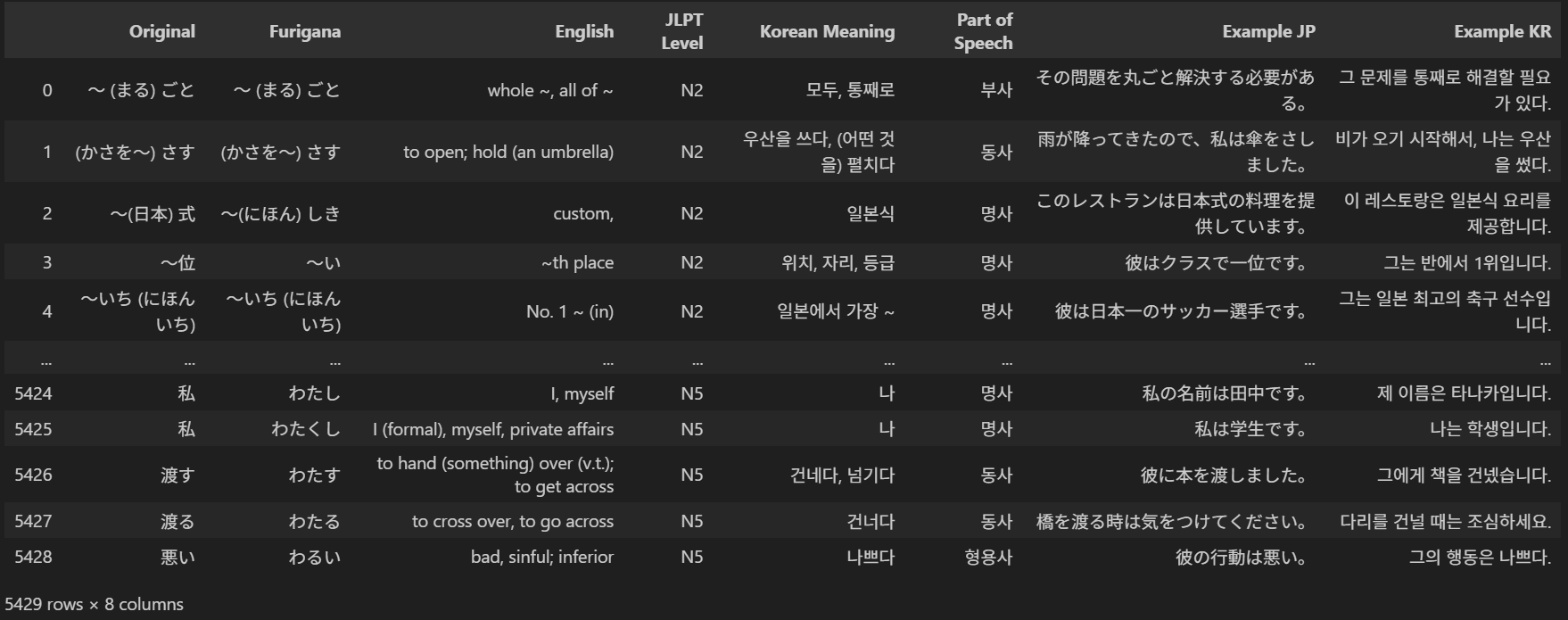
이제 필요한 Column을 추가해보겠습니다.
단어를 공부할 때는 예문도 같이 학습하는게 훨~씬 도움이 되므로 예문도 추가합시다!
따라서 한국어 뜻, 품사, 일본어 예문, 한국어 예문을 추가해서 더 효율적으로 공부해봅시다.
5천개가 넘는 단어 뜻을 일일이 수작업으로 추가하는건 무리니까 우리는 AI의 힘을 빌립시다.
이 정보를 자동으로 추가하기 위해 GPT API를 활용했습니다.
🤖 GPT API를 이용한 데이터 보강
(GPT API 사용법은 추후에 작성하겠습니다)
사용한 모델은 단순 작업이며, API 비용을 줄이기 위해서 mini를 사용했습니다.
- 사용 모델 : GPT-4o-mini
ChatGPT API를 이용해 각 단어에 대해 다음과 같은 정보를 요청합니다. 구체적인 프롬프트는 아래 코드에 있습니다.
- 한국어 뜻
- 품사
- 일본어 예문 (가능하면 쉬운 문장)
- 한국어 번역
답변은 JSON 형식으로 받음으로써, 후에 데이터 처리를 용이하게 했습니다.
🧪 예시
食べる 를 입력으로 사용했을 경우
🧾 기대 출력:
{
"뜻(한국어)": "먹다",
"품사": "동사",
"예문(일본어)": "朝ごはんを食べる。",
"예문(한국어)": "아침밥을 먹다."
}
저는 한글로 출력을 요청하였는데, 한글은 영어보다 토큰 수가 더 많이 들기 때문에, 비용&시간을 줄이기 위해서 영어로 프롬프트를 작성하는게 더 좋습니다.
아래는 GPT API에게 프롬프트를 넘겨주고 답변을 반환하는 함수입니다.
# 🔹 GPT API 요청 함수
def get_word_info(japanese_word):
"""GPT API를 사용해 한국어 뜻, 품사, 예문을 생성"""
prompt = f"""
일본어 단어 '{japanese_word}'의 정보를 제공해줘.
- 뜻을 한국어로 번역
- 품사(명사, 동사 등) 제공
- 일본어 예문 및 해당 예문의 한국어 번역 제공
응답 형식:
{{
"뜻(한국어)": "...",
"품사": "...",
"예문(일본어)": "...",
"예문(한국어)": "..."
}}
"""
try:
response = client.responses.create(
model="gpt-4o-mini",
instructions="You are a helpful Japanese linguist.",
input=prompt,
temperature=0.7
)
result = response.output_text
return parse_gpt_response(result)
except Exception as e:
print(f"❌ 오류 발생: {e}")
return ("", "", "", "")
🚀 GPT 응답 파싱
이제 앞에서 받은 GPT의 응답을 파싱해야합니다.
JSON 파일에서 각 키를 사용해 값을 추출하고, 값이 없는 경우 빈 문자열을 반환하게 해서 오류로 도중에 코드가 멈추지 않게 해줍니다.
# 🔹 GPT 응답을 파싱하는 함수
def parse_gpt_response(response_text):
"""GPT에서 받은 JSON 응답을 뜻, 품사, 예문으로 분리"""
try:
# JSON 문자열을 딕셔너리로 변환
data = json.loads(response_text)
# 각 키에서 값 추출, 값이 없으면 빈 문자열 반환
meaning_kr = data.get("뜻(한국어)", "").strip()
part_of_speech = data.get("품사", "").strip()
example_jp = data.get("예문(일본어)", "").strip()
example_kr = data.get("예문(한국어)", "").strip()
return meaning_kr, part_of_speech, example_jp, example_kr
except json.JSONDecodeError:
# JSON 파싱 실패 시 빈 값 반환
return "", "", "", ""
except Exception as e:
# 기타 오류 발생 시 빈 값 반환
print(f"Error parsing response: {e}")
return "", "", "", ""
파싱 함수를 사용해서 코드를 돌려봅시다!
저는 그냥 for문을 사용해서 코드 돌려놓고 자러갔습니다. 아침에 확인해보니 6시간 12분 46초 걸렸네요.
여러분이 따라하실 때는 저처럼 무작정 for문 돌리지 마시고, csv파일을 10개정도로 쪼개서 멀티쓰레드(MultiThread)로 병렬처리해서 빠르게 처리하시길 바랍니다...
주의 사항 : 데이터 저장시 인코딩을 'utf-8-sig'로 설정하세요! 'utf-8'로 설정하면 글자가 깨집니다.
df = pd.read_csv("vocab_n2_to_n5.csv")
# 🔹 새로운 컬럼 추가
df["Korean Meaning"] = ""
df["Part of Speech"] = ""
df["Example JP"] = ""
df["Example KR"] = ""
# 🔹 데이터 변환 시작
for idx, row in tqdm(df.iterrows(), total=len(df), desc="Processing words"):
word = row["Original"]
english_meaning = row["English"]
# GPT API 호출하여 한국어 뜻, 품사, 예문 가져오기
meaning_kr, part_of_speech, example_jp, example_kr = get_word_info(word)
# 변환된 데이터 저장
df.at[idx, "Korean Meaning"] = meaning_kr
df.at[idx, "Part of Speech"] = part_of_speech
df.at[idx, "Example JP"] = example_jp
df.at[idx, "Example KR"] = example_kr
# API 과부하 방지를 위해 딜레이 추가 (필요 시)
time.sleep(1)
# 🔹 변환된 데이터 저장
df.to_csv(output_file, index=False, encoding="utf-8-sig")
print(f"✅ 변환 완료! 저장된 파일: {output_file}")
반복문이 진행되면서 한 줄씩 데이터가 채워지는 걸 볼 수 있습니다.
이제 한국어 뜻과 예제 등이 포함된 데이터셋을 얻었습니다!
그러면 그것으로 끝일까요?
답변은 아닙니다!
아직 전처리 과정은 끝나지 않았습니다. GPT가 제대로 잘 답변했을지 확인해봐야합니다!
API를 호출하는 과정에서 오류는 발생하지 않았는지? NaN값이 발생하진 않았는지?
저도 도중에 Error code 400 오류가 발생했습니다. 다행히 오류처리를 해놓아서 코드가 끊어지는 불상사는 일어나지 않았습니다.
앞으로 해야할 일은 파싱한 데이터셋을 다시 전처리하는 과정입니다.
AI를 사용하는 경우 전처리가 매우매우 중요합니다!!
⚖️ 데이터셋 전처리 vs 실시간 처리: 어떤 게 좋을까?
끝내기 전에 이런 생각을 한 번 해봅시다.
단어 정보를 GPT로 처리하는 방식에는 두 가지 선택지가 있었습니다.
1. 사전에 데이터셋을 다 가공해놓기 (전처리)
Notion에 넘기기 전에 데이터 전처리 끝내놓는 방법
- ✅ 빠르고 안정적인 자동화 가능
- ✅ 하루치 단어 전송 시 API 사용량 없음
- ❌ 초기 작업 시간이 많이 듦
- ❌ 단어가 추가될 경우 다시 작업 필요
2. 매일 자동 전송 전에 실시간 GPT 호출 (실시간 처리)
추후에 Notion으로 전송할 때 실시간으로 GPT를 호출해서 처리하는 방법
- ✅ 데이터셋 변경에도 유연함
- ✅ API의 최신 모델 활용 가능
- ❌ GPT 호출은 비용 발생
- ❌ 실행 시간 증가
- ❌ 오류 발생 시 유지 보수 비용 발생
결국 저는 전처리 방식을 택했습니다. 어짜피 데이터셋은 고정되어 있고, 도중에 오류가 발생하면 골치아프니까요.
그리고 한 번만 처리하면 되니까요.
🔐 민감 정보는 .env로 관리하자
GPT API 키와 같이 민감한 정보는 코드에 직접 넣지 않고 .env 파일에 따로 저장했습니다.
.env 파일은 .py파일과 같은 디렉토리에 보관하면 됩니다.
### .env 파일
OPENAI_API_KEY=sk-...
그리고 파이썬에서 이를 불러올 땐 python-dotenv 라이브러리를 사용합니다.
from dotenv import load_dotenv
import os
# .env 파일 불러오기
load_dotenv()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
client = OpenAI(
api_key=OPENAI_API_KEY,
)
이렇게 하면 코드도 깔끔하고, 민감 정보가 유출될 위험도 줄어듭니다.
✍️ 마무리하며
이번 글에서는 일본어 단어 암기 자동화를 위해 CSV 데이터셋을 준비하고, GPT API를 통해 단어 정보를 보강한 과정을 공유했습니다.
다음 편에서는 이렇게 가공한 단어 데이터를 다시 한 번 전처리하고, 어떻게 Notion에 자동으로 전송하는지에 대해 소개할 예정입니다.
'AI 활용' 카테고리의 다른 글
| 1편. 일본어 단어 암기, 이제는 자동화다 (0) | 2025.04.09 |
|---|---|
| ChatGPT 쓸 때 좋은 프롬프트 작성법 (0) | 2025.03.06 |